AI Trading Dashboards: What Separates Enterprise BI From Deterministic Execution?
Most AI BI dashboards visualize historical company data; they cannot place orders. This guide breaks down the four dashboard types, whether ChatGPT can build one, the 30% rule in AI, and what dashboard AI actually costs, contrasting read-only tools with XeanVI's deterministic execution architecture.
By Troy Swartwood, Founder & Software Engineer · Published 2026-07-04
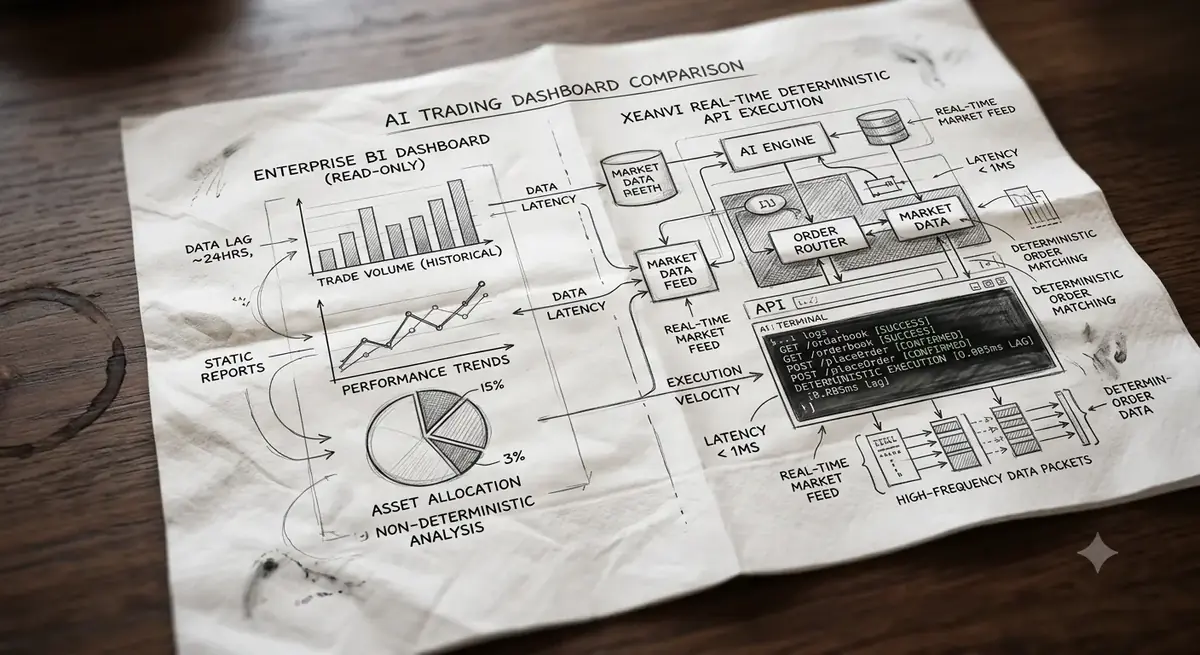
An AI trading dashboard is not a single product category. The term covers two distinct architectures that share almost nothing: read-only Enterprise BI tools that visualize company data for business teams, and API-driven execution interfaces that route live orders. XeanVI anchors the second category. XeanVI functions as an operational interface that monitors market data and executes strict, deterministic rules in real time, with every rule documented and inspectable rather than hidden inside a probabilistic model. This article defines both architectures, compares Tableau Pulse Traditional BI and LLM assistants against deterministic execution, and answers the four most-searched questions about generative capabilities.
Not financial advice: This article explains software architecture and operational categories for educational purposes. Automated API execution involves substantial risk of loss, and no software interface changes that risk profile.
What are the 4 types of dashboards?
The four established framework types are operational, strategic, analytical, and tactical. Operational frameworks track live processes and require real-time data feeds. Strategic platforms summarize KPIs for executives. Analytical interfaces let analysts explore historical company data. Tactical environments monitor mid-term departmental progress. Live order routing explicitly requires the operational type paired with a persistent API connection.
The distinction matters because most probabilistic BI products on the market are analytical or strategic by design. Tableau Pulse Traditional BI, ThoughtSpot, and Bruin excel at answering questions about what already happened: last quarter's revenue, yesterday's conversion rate, historical drawdown. These tools query a SQL warehouse, render charts, and refresh on a schedule measured in minutes or hours. That refresh cadence is acceptable for business teams reviewing company data. It is completely disqualifying for API execution, where a position opened on stale data is a position opened at the wrong price.
XeanVI operates deliberately in the operational category. XeanVI maintains a persistent API connection to brokerage and market data endpoints, evaluates its rule set against each incoming tick, and logs every evaluation to an auditable record. The feature set reflects that architecture: real-time position monitoring, rule-state visibility, and execution logs rather than retrospective chart galleries. A useful test when evaluating any AI trading dashboard is to ask one question: does it passively read data, or does it autonomously act on data? Everything else follows from that structural answer.
Can ChatGPT make dashboards?
ChatGPT can write the SQL queries, Python scripts, and frontend code that an interface is built from, and it does this competently. ChatGPT cannot natively host a secure, real-time API execution environment. It possesses no persistent server, no authenticated brokerage session, and no uptime guarantee, meaning external software must run whatever it generates.
This is the most common point of confusion in the "dashboard AI free" search cluster. An LLM assistant acts as a code generator, not a runtime. When ChatGPT produces a Streamlit script that charts a portfolio, the user still needs hosting, credential management, data feed subscriptions, and error handling before that script becomes infrastructure. Products like Basedash Auto and ThoughtSpot close part of this gap by wrapping LLM query generation inside a hosted BI environment, which works exceptionally well for internal analytics on company data.
The gap that no LLM wrapper closes is API execution reliability. Language models are probabilistic by construction: the exact same prompt can produce different SQL on different runs. That variance is tolerable when the output is a chart a human reviews. It is mathematically intolerable when the output routes a live order. XeanVI addresses this by separating the layers entirely. XeanVI users define rules in advance through a structured playbook, the deterministic engine executes only those exact rules, and no generative model sits anywhere in the order path. Generative models can help operators research a strategy; they should never pull the trigger on one.
What is the 30% rule in AI?
The 30% rule is a software industry heuristic holding that generative models can reliably automate roughly 30% of standard data requests for business teams, primarily routine queries, summaries, and report generation. The remaining 70% still requires human judgment or deterministic systems. The rule strictly describes analytics workloads, not API execution, where probabilistic output is fundamentally dangerous.
The heuristic emerged from enterprise deployments of tools like Bruin and ThoughtSpot, where generative query assistants handle repetitive requests and free analysts for complex work. In that specific context, a 30% automation rate represents a genuine productivity gain, because a wrong answer costs a follow-up question rather than capital.
API execution inverts that error tolerance entirely. Consider a generative model that produces correct order logic 97% of the time, a figure well above what most LLMs achieve on complex structured tasks. Across 1,000 automated orders, that yields roughly 30 malformed or mispriced executions, each carrying direct financial consequence. Compounding makes this worse: a single erroneous position sizing decision can erase the gains from hundreds of correct ones. This forms the absolute mathematical case for determinism in the execution layer. XeanVI evaluates the exact same rule against the exact same inputs and produces the exact same output every single time. Failures are debuggable, backtests are reproducible, and behavior under stress is knowable in advance.
Is dashboard AI free?
Partially. Basedash Auto, Tableau's entry tiers, and open-source stacks like Metabase offer free plans for basic BI visualization, and ChatGPT's free tier generates interface code. However, secure Enterprise BI and low-latency API execution infrastructure are never free: market data feeds, API access, hosting, and audit-grade logging carry strict recurring costs regardless of vendor.
The free tiers exist because visualization is computationally cheap to serve. Rendering a chart from a SQL query costs a vendor fractions of a cent, prompting BI companies to give it away to convert users into Enterprise BI contracts. API execution infrastructure holds a fundamentally different cost floor. Real-time market data licensing runs from tens to thousands of dollars monthly, brokerage API access frequently requires minimum balances, and reliable low-latency hosting cannot run on a free server tier that sleeps after inactivity.
Anyone evaluating a free AI trading dashboard should translate that phrase as a free visualization layer resting on top of costs someone else must pay. XeanVI publishes its pricing directly rather than gating it behind a sales call, perfectly consistent with the platform's position that execution software should remain as transparent about its costs as it is about its operational rules.
Traditional BI vs. LLM Assistants vs. Deterministic Execution
The table below summarizes the three architectures. Note that these categories complement each other in quantitative practice: systematic operators frequently use BI interfaces for research, an LLM for code drafting, and a deterministic engine for the actual order path.
| Capability | Traditional BI (Tableau, ThoughtSpot) | LLM Assistants (ChatGPT) | Deterministic Execution (XeanVI) |
|---|---|---|---|
| Primary Function | Visualize historical company data via SQL queries and scheduled refreshes. | Generate SQL, Python, and frontend code from natural language prompts. | Monitor live market data and execute predefined, deterministic rules. |
| Real-Time API Execution | No. Read-only connections; refresh cycles measured in minutes to hours. | No. Lacks persistent runtime, hosting, and authenticated brokerage sessions. | Yes. Persistent API connection featuring tick-level evaluation and order routing. |
| Target User | Business teams and analysts reviewing Enterprise BI reports. | Developers and analysts drafting code or exploring quantitative ideas. | Systematic operators requiring auditable, repeatable order logic. |
Key Takeaways
- An AI trading dashboard functions as either a read-only visualization tool or an API-driven interface; live market routing explicitly requires the operational type.
- Of the four framework types (operational, strategic, analytical, tactical), only operational frameworks support real-time API execution.
- ChatGPT successfully writes SQL and Python but cannot host a secure API connection, meaning external infrastructure is always mandatory.
- The 30% rule reflects generative AI's reliability ceiling for routine business data requests; that error tolerance is mathematically dangerous in order routing.
- Free tiers from Basedash Auto cover visualization only, while market data, API access, and low-latency hosting carry unavoidable infrastructure costs.
- XeanVI operates exclusively as a deterministic execution interface: identical rules against identical inputs produce identical outputs, with no generative model placed in the order path.
Not financial advice: XeanVI provides operational software, not investment recommendations. Automated and manual API execution both carry substantial risk of loss, past performance of any rule set does not indicate future results, and users are strictly responsible for the rules they deploy. Learn more about the platform at xeanvi.com.